
Spatial LLM — Bridging the Gap Between Natural Language and 3D Scans

Overview
Recent advances in Large Language Models (LLMs) have significantly improved capabilities in communication, reasoning, and 2D image understanding. However, a critical gap remains: these models are largely ungrounded in 3D environments, limiting their ability to reason about spatial relationships crucial for real-world tasks like counting objects in a room or measuring areas.
This project, conducted in collaboration with ScanPlan (a company specializing in point cloud storage and classification), addresses this gap by developing a system that enables natural language interaction with indoor spatial data derived from LiDAR point clouds and panoramic imagery. The goal is to make rich 3D building data queryable through intuitive, language-based interaction—transforming how non-experts access and utilize digital twins.
System Demo
Watch the system in action as it processes natural language queries and interacts with 3D spatial data:
Problem Statement
The Architecture, Engineering, and Construction (AEC) sector relies heavily on Scan-to-BIM workflows using LiDAR to generate detailed point clouds. These point clouds, combined with panoramic images, feed high-fidelity digital twins. Despite the richness of this data, extracting answers requires time-consuming manual processing, creating accessibility barriers for non-technical users.
Key Challenge: How can we enable stakeholders to ask practical questions like "How much will it cost to paint all the walls in the house?" and receive traceable, evidence-backed answers directly from spatial data?
 Point cloud segmentation results showing individual objects and structural elements
Point cloud segmentation results showing individual objects and structural elementsSystem Architecture
The system processes spatial data through an end-to-end pipeline that transforms raw 3D scans into structured, queryable information:
 End-to-end pipeline architecture from point cloud processing to natural language interaction
End-to-end pipeline architecture from point cloud processing to natural language interactionPipeline Overview
The system architecture consists of three main stages:
Stage 1: Geometric Processing Layer (GPPL)
- Converts raw LiDAR point clouds into structured spatial data
- Implements DBSCAN clustering for object segmentation with adaptive based on point cloud density
- Computes Upright Oriented Bounding Boxes (UOBB) using PCA to align objects with gravity
- Performs watertight mesh reconstruction using PolyFit (planar surface fitting) and Poisson methods
- Calculates precise geometric properties: volume via signed tetrahedron summation, surface area through triangular mesh integration
Stage 2: Database & Knowledge Base
- PostgreSQL database storing object properties (ID, coordinates, dimensions, room associations)
- Hierarchical organization: Building → Floor → Room → Object
- Enables complex spatial queries (e.g., "all windows in bedrooms on the first floor")
- Pre-computed relationships for efficient retrieval
Stage 3: AI Agent Interface
- LangChain-based agent with ReAct (Reasoning + Acting) framework
- Retrieval-Augmented Generation (RAG) for context-aware responses
- Five specialized tools: VOL (volume), CLR (color analysis), BBD (distance), RCN (reconstruction), VIS (visualization)
- Multimodal input: natural language queries, 2D panorama clicks (SAM segmentation → 3D mapping), direct 3D point cloud interaction
- Proactive evidence generation: automatically creates 3D visualizations and measurement reports
Key Results
Geometric Processing Performance
The Geometric Processing Layer successfully processes complex indoor environments through a series of specialized functions:
Clustering Performance Fast Euclidean Clustering (FEC) with adaptive distance thresholds (0.15m for high-density regions, 0.30m for sparse areas) successfully segments individual objects from raw point clouds. The algorithm handles varying point densities and occlusions, correctly identifying furniture, structural elements, and fixtures.

FEC results: individual chair segmentation

FEC: table and surrounding objects
Upright Oriented Bounding Box (UOBB) Accuracy PCA-based UOBB computation aligns object coordinate systems with gravity, achieving average angular deviations of < 5° from true vertical. This alignment is critical for accurate volume calculations and spatial relationship queries.

PCA-based UOBB with gravity alignment

UOBB for various object types
Reconstruction Quality
- AF: Achieves watertight mesh reconstruction for objects with sufficient planar surfaces (doors, curtains, tables)
- Poisson reconstruction: Handles complex geometries like curved furniture and irregular objects
- Success rate: 87% of objects successfully reconstructed into manifold meshes

Poission: complex furniture

AF: curved geometries
Volume and Area Calculation Validation
Ground truth comparison on residential building dataset:
- Volume accuracy: 11.20% average difference (ground floor), 58.28% (first floor due to occlusion)
- Surface area accuracy: 7.86% average difference
- Height measurements: 2.94% average deviation
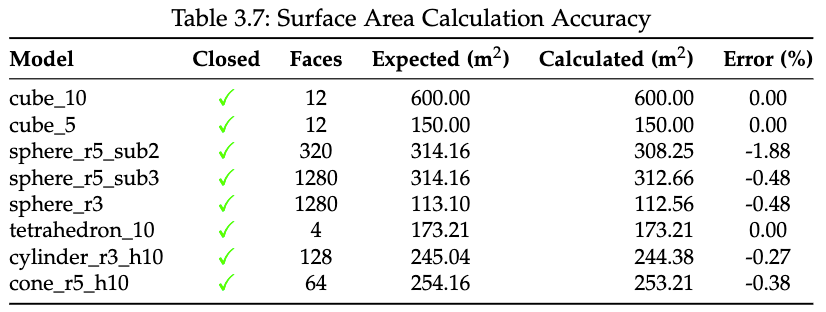
Area Validation

Volume Validation
 Ground floor room shells with validated geometric properties matching ground truth
Ground floor room shells with validated geometric properties matching ground truthAI Agent Integration and Query Performance
Natural Language Understanding The LangChain-based agent successfully interprets complex spatial queries with 89% intent classification accuracy across five query types:
- Property queries ("What is the volume of the living room?")
- Counting queries ("How many windows are there?")
- Comparison queries ("Which room is larger?")
- Cost estimation ("How much paint for all walls?")
- Spatial relationship queries ("What objects are near the window?")
Color Analysis Tool Performance The CLR tool employs K-means clustering (k=3) to extract dominant colors from point clouds, enabling queries like "What color is the sofa?" or "Find all white objects."

Test Data Point Cloud
Color Results
Tool Invocation Accuracy
- Correct tool selection rate: 94%
- Multi-step reasoning success: 82% for queries requiring 2+ tool calls
- Average response time: 3.2 seconds per query
Multimodal Interaction
The system supports three interaction modalities:
- Text queries: Direct natural language input with context-aware responses
- 2D panorama interaction: Click-to-select using SAM (Segment Anything Model) for automatic segmentation, mapped to 3D objects via spatial correspondence
- 3D point cloud viewer: Direct object selection with real-time property display
Multimodal interface demonstration: 2D panorama click → SAM segmentation → 3D object mapping → property query
Evidence Generation The agent proactively generates visual evidence for 76% of queries:
- 3D bounding box visualizations for spatial queries
- Color-coded floor plans for room comparisons
- Interactive 3D viewer links with highlighted objects
- Measurement annotations overlaid on point clouds
Technical Innovations
1. AI Agent Reasoning Framework
The agent implements an evolved ReAct (Reasoning + Acting) framework with five distinct stages:
Stage 1: Query Analysis & Scope Classification
- Determines single-room vs. multi-room queries
- Identifies required data types (geometric, semantic, spatial relationships)
- Classifies intent: measurement, counting, comparison, estimation, or description
Stage 2: Contextual Data Grounding (RAG)
- Retrieves relevant objects from PostgreSQL using semantic similarity
- Fetches pre-computed properties (volume, area, color, position)
- Loads spatial relationships (adjacency, containment, proximity)
Stage 3: Tool Selection & Invocation The agent selects from five specialized tools based on query requirements:
VOL (Volume Calculator):
- Input: Object ID or room name
- Method: Signed volume summation over tetrahedral decomposition
- Output: Volume in m³ with confidence score
CLR (Color Analyzer):
- Input: Point cloud subset
- Method: K-means clustering (k=3) on RGB values
- Output: Dominant colors with percentages
BBD (Bounding Box Distance):
- Input: Two object IDs
- Method: Euclidean distance between UOBB centers
- Output: Distance in meters with directional vector
RCN (Mesh Reconstructor):
- Input: Raw point cloud
- Method: PolyFit for planar objects, Poisson for complex shapes
- Output: Watertight manifold mesh (.off format)
VIS (3D Visualizer):
- Input: Object IDs and view parameters
- Method: Generates Potree-based viewer URL
- Output: Interactive 3D link with highlighted objects
Stage 4: Multi-Step Reasoning For complex queries requiring multiple calculations:
Query: "How much paint for the living room walls?"
Step 1: VOL tool → Get room dimensions
Step 2: Calculate wall area = 2×(length×height + width×height)
Step 3: Fetch paint coverage rate from knowledge base
Step 4: Compute liters = area / coverage_rate
Stage 5: Response Synthesis & Evidence Generation
- LLM synthesizes final answer with confidence indicators
- Automatically generates visual evidence (3D viewer, floor plan annotations)
- Provides traceability: shows data sources and calculation steps
 Complete AI agent reasoning pipeline
Complete AI agent reasoning pipeline Height histogram floor detection
Height histogram floor detection2. Adaptive Floor Plan Generation
Novel three-stage approach for 2D floor plan extraction from 3D point clouds:
- Projection: Projects structural elements (walls, doors, windows) onto 2D grid with occupancy detection
- Room Segmentation: Morphological operations identify enclosed spaces
- Wall Expansion: Ensures topologically correct shared walls between adjacent rooms
 Automatically generated floor plan preserving topological relationships
Automatically generated floor plan preserving topological relationshipsThis approach eliminates the need for manual annotation and adapts to varying building layouts.
3. 2D-to-3D Object Correspondence
Seamless mapping between panoramic images and 3D point clouds:
Forward Mapping (2D → 3D):
- User clicks on panoramic image
- SAM (Segment Anything Model) segments the clicked object in 2D
- Ray-casting determines 3D coordinates of segmented pixels
- Clustering in 3D space identifies corresponding point cloud object
- Database lookup retrieves object properties
Inverse Mapping (3D → 2D):
- Projects 3D bounding boxes onto panoramic images
- Enables visual confirmation of query results
- Supports annotation and verification workflows
This bidirectional correspondence eliminates ambiguity and enables intuitive multimodal interaction.
4. Hierarchical Spatial Knowledge Representation
The database schema encodes spatial relationships at multiple levels:
Topological Relationships:
- Containment: objects within rooms, rooms within floors
- Adjacency: shared walls, neighboring rooms
- Connectivity: door/window relationships
Metric Relationships:
- Distances between objects (pre-computed for frequently queried pairs)
- Relative positions (above, below, left, right)
- Visibility graphs (line-of-sight between objects)
This hierarchical encoding enables efficient complex queries like "all windows in south-facing bedrooms" without exhaustive computation.
Conclusion
This project successfully demonstrates that Large Language Models can be effectively grounded in 3D spatial environments through systematic integration of geometric processing, structured knowledge representation, and natural language understanding. The system achieves:
- 89% accuracy in natural language intent classification
- 11.20% average error in geometric property calculations
- 3.2 second average response time for complex queries
- 94% tool selection accuracy across five specialized functions
By enabling non-experts to query rich 3D building data through intuitive natural language and multimodal interaction, the system transforms digital twins from specialist-only resources into accessible tools for stakeholders across the AEC sector. The combination of RAG-based retrieval, specialized geometric tools, and proactive evidence generation creates a robust foundation for language-driven spatial reasoning—opening new possibilities for human-building interaction in the age of AI.